
Creating an AI Roadmap: An Algorithmic Approach
(And a rant on vague advice) - part 3 in a series on AI value in the enterprise

I love archery.
Living in New York City, I don’t get to do it very often.
But, entertaining boyish fantasies of shooting arrows - backwards, on a moving horse, like a Dothraki raider - a silly thought occurred to me.
Success with AI is just like shooting arrows.
Stay with me.

You need a clear target (biz outcome).
A stable stance (foundational capabilities).
An unwavering gaze (saying “no” to distractions).
Loosing (shooting) an arrow - execution - balances relaxation (experimentation) & tension (delivery).
You do all this with limited shots (finite resources).
Most importantly:
You can only hit one target at a time.
More than any other type of technology project - with the possible exception of product dev at a startup - applied AI projects require and reward the concentration of resources. They will reveal all the cracks in your foundation: people, process, technology, data. On the flip-side, they also take well to parallelization if planned effectively.
This is why the typical enterprise “shotgun” approach of trying to do everything at once falls flat so frequently. Scaling AI requires depth before breadth.
One successful delivery creates more reusable knowledge and components than 10 POCs:
Delivered 1 pricing model? Reuse in a different market.
Delivered 1 OCR solution? Reuse with different doc types.
Delivered 1 fraud detection framework? Reuse in a different line of business.
(Not every component of an AI project is reusable, of course. But I digress.)
In the first article of this series, you found an area to focus on based on potential business impact and the story success would let you tell (steps 1 & 2). In Part 2, you took a process engineering approach to find the best opportunities within that area to target for AI transformation (step 3).
All of this is done before a single line of code is written.
Today, you’ll learn to “draw your bow,” i.e., create a rational execution roadmap for AI delivery
...against a specific business process
...to drive specific KPI improvements
This is the immediate step before execution.
Please don’t skip this part and just start doing random shit
By now, you’ve probably realized I have a vendetta against “doing random shit.”
People’s time matters.
Doing things that matter matters.
And having a structured approach matters.
Indeed, this is not fluffy advice to “work with stakeholders” and “build momentum.” You already know that stuff because you have a brain.
No.
This is an algorithmic approach to targeted AI roadmap development. I use words like “sort,” “filter,” and “iteration.” I’m a data scientist, and this is how I think. If you don’t like it, I’m sure Gartner has another “exclusive report” on “Unlocking AI’s Potential” with your name on it.

I followed this process in my last company to reprioritize AI work, get buy-in across wildly diverse teams (software engineers, project management, SMEs, business leaders, finance, risk partners, etc.), get funding, and shift the organization’s mindset away from old “digital delivery” paradigms towards an “AI delivery” paradigm, as Vin Vashishta might put it.
The stronger you draw your bow (roadmap), the more “tension” you’ll release in your team when you kickoff, and the deeper your solution will penetrate.
Depth before breadth.
If you’re ready to target (or retarget) your AI initiatives to achieve real, defensible ROI, this is for you.
Step 4 - Brainstorm and prioritize solutions by bottleneck
In step 3, we created a process diagram of a key business process, with throughput numbers. We used the process diagram to find big bottlenecks and early bottlenecks. We also captured notes on process nuance and edge cases by job shadowing SMEs.
Both are necessary for brainstorming and prioritizing solutions.
The goal of step 4 is to begin work on the most feasible solution to the most important problem - that is, the most critical bottleneck.
We begin with brainstorming solutions to the identified bottlenecks. I will reference the document processing use case I was working with throughout.
The wrong approach here (that everyone does) is brainstorming haphazardly and jumping on the first feasible approach.
Everyone prioritizes wrong
Project managers in particular over-index on quick wins to show progress - because it’s their job to show progress.
Data scientists and other technical ICs over-index on coolness (technical sophistication or novelty) - because they want to learn and apply new techniques and think it’s how they get promoted (often it’s not).
Business over indexes on impact without considering feasibility - because they’re the end users and don’t understand how the sausage gets made.
Think of a table with 5 columns:
bottleneck
impact of solving bottleneck (process KPI #)
solution
feasibility of solution (1-10)
“coolness” of solution (1-10)
Project managers sort by feasibility.
Technical ICs sort by coolness.
Business sorts by impact.
None are right.
Focus on impact, then feasibility, iteratively
The Goldilocks approach puts feasibility and coolness in their proper place - within the context of impact. The right general approach is:
Sort by impact (bottleneck), then by feasibility (of solution), then by coolness (of solution). Usually, the first 2 are enough (sorry ICs). This is done iteratively in a very particular way. There’s a lot here, so I will walk through the steps and then summarize at the end.
You start with your most impactful bottleneck. Then, brainstorm solutions to it. It’s likely 1 solution will not solve the entire bottleneck, so you break it down into easier core and harder (known) edge cases.
Consider our example process diagram from the last article here:
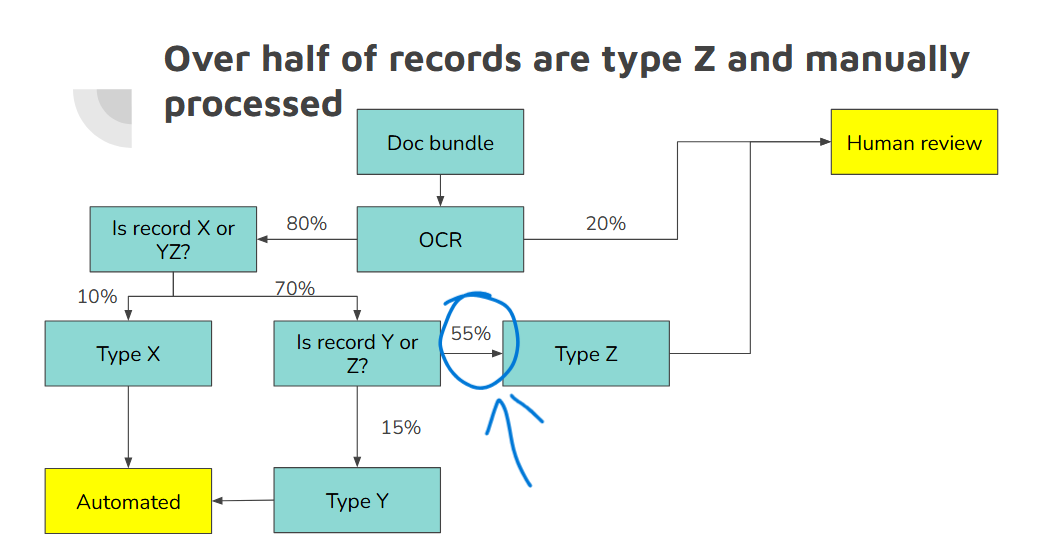
Like the diagram here, we did have one large and obvious bottleneck to focus on that would drive the most improvement to the KPI (% of docs handled automatically). Unsurprisingly, not all cases could be tackled at once: there were “core” and “edge” cases.
The job shadowing notes are critical here. Why edge cases are harder to solve and what it would take to handle each case. Specifically, you must know what knowledge is needed, and does that knowledge exist as data somewhere? Examples:
If required knowledge is only in people’s heads, you need to get it down in an accessible system somewhere.
If knowledge is scattered across systems-of-record, you need to connect that data in one place.
After breaking down the bottleneck, brainstorm solutions for each component.
As always, vagueness is the enemy here. It’s not just “process documents with AI.” It’s “extract these 24 key: value pairs required to make a decision with X% accuracy.” Every solution is, at its heart, a hypothesis with clear success criteria, tied to one or more business KPIs, that may or may not be falsified during execution.
This is an iterative process that much be performed with technical experts and business SMEs. Why? What’s easier (core) vs. harder (edge) cannot be fully known at the beginning. It depends on:
The nature of the solution (known before experimentation). For example, using classical ML techniques might require training 1 model for each of 5 document types, while an LLM may be able to handle more cases out-of-the-box.
The solution’s performance (known after experimentation). Maybe the LLM will perform well on 3 of the 5 cases/doc types, but not the last 2 without more data retrieval, prompt engineering, or something else. The LLM might also surface a 6th hard-to-handle type that went unidentified before.
In either case, the bottleneck cannot be broken down into its parts for reprioritization until those experiments are conducted. In our example, note the 5 known cases as part of a single solution for now.
Discover non-AI opportunities, too!
One of the great advantage of a process-oriented approach to AI injection is that it unearths many non-AI opportunities. Entertain at least the following categories:
data: improving underlying data
technology: improving hard-coded automations & workflow
process: refactoring or eliminating unnecessary steps
people: what will people do differently as a result of these solutions
The items in this list may look familiar to you. It’s the PPTD (people, process, technology, data) framework, which gives a holistic view of aspects to consider in any digital transformation.
Different teams will own different aspects of these solutions. By involving these teams in the solutioning, you may also grow your influence and develop stronger cross-functional relationships, a key element of effectiveness and promotion.
Some teams and titles to consider:
data: data stewards, data engineers, data & business analysts
technology: platform engineering, cyber security, user experience
process: business SMEs & sponsors, risk & control partners
people: business SMEs & sponsors
Map dependencies
This breakdown process will reveal dependencies, especially as you also consider non-AI solutions. For example, you may need to cleanup and centralize your data in order to tackle edge cases 4 and 5. These dependencies limit how the work can be parallelized later. They also make prioritization easier by reducing the number of starting points.
Our project had plenty of dependencies and underlying data work. We also discovered high-impact low-hanging fruit in our rules automations.
Filter and sort solutions
After you’re done breaking down the bottlenecks into their parts, filter out solutions that are infeasible and bottlenecks with dependencies on other solutions. Think of this as a hard cutoff, like feasibility < 5 and hasDependency = True.
Finally, you resort your list again by impact and then by feasibility, then distribute and execute work in this order.
By the end of all this process, we reduced the problem space to less than 5 (!) testable hypotheses, some of which depended on the others.
Become the (Spark) Driver
If there’s only enough people to work on 1 workstream at a time, you work on the solution at the top of the list.
If there’s enough folks to parallelize 5 ways, you divide the work among the 5 teams/individuals. Parallelization is beneficial but not required.
If this sounds a bit like the execution of a distributed Spark job, you’re right!
In this way, you start work on the most feasible solution to the most important problem. You also have a clear roadmap for what you’ll handle next (solutions with dependencies & solutions further down the list), and how roadmap items will improve KPIs (tied to process throughput numbers).
Your 8-step action plan for creating a targeted AI roadmap
That was a lot. The steps, summarized are:
Sort bottlenecks by impact
Break bottlenecks into core and edge cases, with impact (KPI) numbers
Brainstorm solutions to core and edge cases
Include non-AI solutions using the PPTD (people, process, technology, data) framework and involve relevant partners
Indicate if certain bottlenecks/solutions have dependencies
Example: solving the edge cases requires solving the core case first
Repeat steps 2 - 4 until the bottlenecks cannot be broken down any further
Filter out relatively infeasible solutions and anything that can’t be started (i.e., that has dependencies)
Sort list by impact and feasibility
Distribute work in parallel based on resources
Along the way, involve folks from other teams as necessary.
Some final notes
Process vs. product-focus
I’ve focused thus-far on operational improvement and process reengineering. This is where most enterprises and larger, older organizations will start because it’s lower risk and allows for more defensible ROI calculations. Done right, it can still result in considerable improvements to the customer experience and create a compelling story in the market. Startups and smaller, less-risk-averse orgs will probably want to take a product-oriented approach.
Large orgs build trust and guardrails with process reengineering, which then lets them tackle product and external-facing use cases with less risk.
Be bureaucracy-invariant
This process can be as lightweight or heavyweight as you want. You could map all this stuff in JIRA/Azure DevOps, a spreadsheet, document, or slides. What matters is the thinking and the principles behind it, and documenting it somewhere for reference.
In other words, this process is bureaucracy-invariant.
This is not a “functional capabilities” roadmap
Many people interpret “AI roadmap” as a set of functional capabilities. Things like “OCR,” “audio transcription,” “dynamic pricing,” “model governance” and the like.
As you might have noticed, this is not that kind of roadmap. In the absence of a clear business case and scale potential (reusability), getting buy-in and funding for these capabilities is a nightmare. I tried.
Instead, I suggest creating functional roadmaps backwards from these business/process-specific AI roadmaps. You develop a new capability that serves a specific business (call summarization and intent classification in the call center), then scale it elsewhere.
Partly, this is the price we in data must pay for our historic (and, often, current) lack of a commercial mindset.
That’s all for this week.
This was a heady one. I felt like I was writing a chapter in a book!
Let me know what you think in the comments (or DM or email me). Also, consider saving this article for reference later.
Good luck!
I've experienced the emotional rollercoaster of getting Data Scientists/adjacent teams PUMPED about our cool Data Science Roadmap, only to watch the team settle back into usual disappointment when it gathered dust, our top priorities outmuscled by new projects. It was easy to get cordial buy-in when presenting the roadmap to VPs in the abstract, and then I saw it get shoved aside by new opportunities with real money.
This article has helped me see that even though for each functional capability I had a little box with "Impact" with a high score and a linked KPI, the link to impact, specifically what process or opportunity would see value, was never really all that clear to the VPs. And that should have been THE thing framing the whole discussion. This is a much better approach to really grabbing and keeping attention to move these initiatives forward!
I'm glad you like it! Changing numbers is one thing, but changing the product and processes changes the "story" that leaders can tell.
Tactical tip to reduce new projects outmuscling the old: bring up the opportunity cost. Say "if we do this, we won't do that, which had x benefits. Which do you think is more important?" Make it a discussion and force them to make the call on tradeoffs. That's why my gold standard platonic ideal for prioritization is "work on something so important the ceo would feel like an idiot to put you on something else."